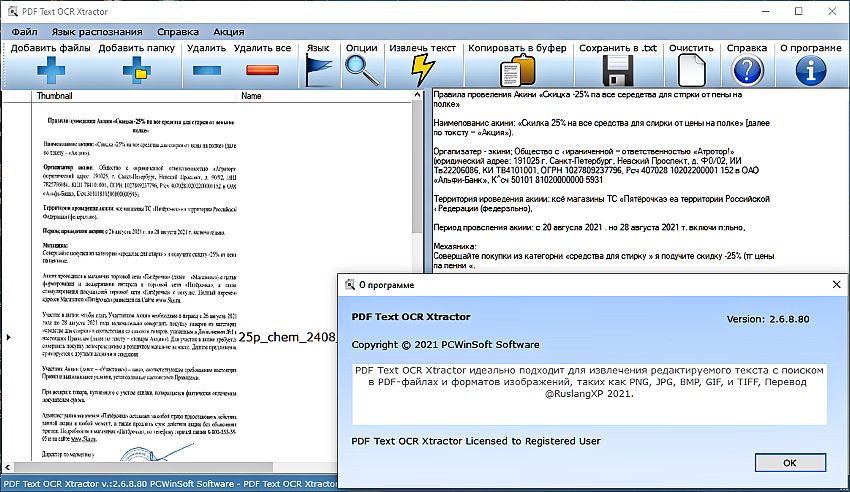
Как вытащить из пдф текст: Копирование содержимого PDF в Adobe Reader
Из PDF в текст — Бесплатный PDF-конвертер онлайн
OCR позволяет извлечь текст из любого PDF-документа. Преобразуйте PDF в текстовый документ — работать с текстом будет гораздо проще.
Перетащите файлы сюда
Введите URL
Dropbox
Google Диск
Исходные языки файла
Чтобы получить оптимальный результат, выберите все языки, которые есть в файле.
Применить фильтр:
Применить фильтр
No FilterGray Filter
Информация: Включите поддержку JavaScript, чтобы обеспечить нормальную работу сайта.
Публикация рекламы
Оставайтесь на связи:
Как преобразовать PDF в текст?
- Загрузите PDF.
- Выберите язык документа из меню (по желанию).
- Нажмите «Начать» и дождитесь завершения преобразования.
Оцените инструмент
3. 9 / 5
9 / 5
Чтобы оставить отзыв, преобразуйте и скачайте хотя бы один файл
Отзыв отправлен
Спасибо за оценку
Извлечение текста из PDF в Python | Средство извлечения текста из PDF на Python
Вам, как программисту, может понадобиться обработать кучу PDF-файлов и извлечь из них текст. Извлечение текста из PDF может потребоваться для различных целей, таких как анализ текста. В этой статье мы собираемся продемонстрировать, как легко извлечь текст из файла PDF в Python. Кроме того, вы узнаете, как извлечь текст и сохранить его в файл TXT.
- Библиотека Python для извлечения текста из файлов PDF
- Как извлечь текст из PDF
- Извлечение текста из PDF в Python
Aspose.Words for Python — замечательная библиотека, позволяющая легко создавать и обрабатывать текстовые документы. Вы можете работать с документами популярных форматов, таких как DOC, DOCX и PDF. Мы собираемся использовать эту библиотеку для извлечения текста из наших файлов PDF. Вы можете установить библиотеку из PyPI с помощью следующей команды pip.
Вы можете работать с документами популярных форматов, таких как DOC, DOCX и PDF. Мы собираемся использовать эту библиотеку для извлечения текста из наших файлов PDF. Вы можете установить библиотеку из PyPI с помощью следующей команды pip.
> pip install aspose-words
Aspose.Words for Python сделал извлечение текста PDF чрезвычайно простым, скрыв сложные операции от пользователя. Вам нужно только загрузить файл PDF и сохранить извлеченный текст. Следующие шаги демонстрируют, как извлечь текст из PDF-файла с помощью Aspose.Words for Python.
- Загрузите файл PDF из нужного места.
- Извлеките и сохраните текст в файл .txt.
И это все. Затем вы можете обработать файл .txt и манипулировать простым текстом, извлеченным из PDF.
Давайте теперь посмотрим, как программно извлечь текст из PDF в Python.
Ниже приведены шаги, а также классы и методы для извлечения текста PDF в Python.
- Загрузите файл PDF, используя класс Document.
- Извлеките текст из PDF в файл .
 txt, используя метод Document.save(fileName).
txt, используя метод Document.save(fileName).
 txt, используя метод Document.save(fileName).
txt, используя метод Document.save(fileName).В следующем примере кода показано извлечение текста из файла PDF в Python.
# Импорт Aspose.Words для модуля Python
import aspose.words as aw
# Загрузить PDF-файл
pdf = aw.Document("file.pdf")
# Извлечение и сохранение текста в файле TXT
pdf.save("extracted-text.txt")
На следующем снимке экрана показан входной файл PDF, который мы использовали для извлечения текста.
На следующем снимке экрана показан извлеченный текст в файле TXT.
PDF Text Extractor для Python — получите бесплатную лицензию
Вы можете получить бесплатную временную лицензию для извлечения текста из PDF без ограничений пробной версии.
Вывод
В этой статье вы узнали, как извлекать текст из файлов PDF в Python. Вы видели, как легко и быстро можно извлечь текст из PDF и сохранить его в файле TXT программными средствами. Теперь вы можете реализовать извлечение текста для пакета PDF-файлов в своих приложениях Python.
Вы можете изучить другие функции Aspose. Words for Python, используя документацию. Если у вас возникнут какие-либо вопросы, дайте нам знать через наш форум.
Words for Python, используя документацию. Если у вас возникнут какие-либо вопросы, дайте нам знать через наш форум.
Смотрите также
- Создавайте документы MS Word с помощью Python
- Преобразование документа Word в HTML с помощью Python
- Преобразование документов Word в PNG, JPEG или BMP в Python
- Документы Word в Markdown с использованием Python
- Сравните два документа Word в Python
Как извлечь текст из PDF. Научитесь использовать Python для извлечения текста… | Костас Андреу
Научитесь использовать Python для извлечения текста из PDF-файлов
Фото Карла Хейердала на Unsplash
В этом блоге мы рассмотрим самые популярные библиотеки для обработки PDF-файлов с помощью Python. Много информации передается в формате PDF, и часто нам нужно извлечь некоторые детали для дальнейшей обработки.
Чтобы помочь в моем исследовании по выявлению самых популярных библиотек Python, я просмотрел StackOverflow, Reddit и, как правило, множество поисковых запросов в Google. Я определил множество пакетов, каждый со своими сильными и слабыми сторонами. В частности, пользователи в Интернете, похоже, используют: PyPDF2, Textract, tika, pdfPlumber, pdfMiner.
Я определил множество пакетов, каждый со своими сильными и слабыми сторонами. В частности, пользователи в Интернете, похоже, используют: PyPDF2, Textract, tika, pdfPlumber, pdfMiner.
Однако во время моего исследования по той или иной причине мне удалось заставить только 3 из этих библиотек работать должным образом. Для некоторых из этих библиотек настройка была слишком сложной (отсутствующие зависимости, странные сообщения об ошибках и т. д.)
Давайте все же быстро просмотрим все эти библиотеки.
Оценка: 3/5
Хорошей новостью с PyPDF2 было то, что установить его было очень просто. В документации немного не хватает простых примеров для подражания, но будьте внимательны, и в конце концов вы сможете во всем разобраться.
Плохая новость заключается в том, что результаты были невелики.
Как видите, он определил правильный текст, но по какой-то причине разбил его на несколько строк.
Код:
import PyPDF2fhandle = open(r'D:\examplepdf.
 pdf', 'rb')pdfReader = PyPDF2.PdfFileReader(fhandle)pagehandle = pdfReader.getPage(0)print(pagehandle.extractText())
pdf', 'rb')pdfReader = PyPDF2.PdfFileReader(fhandle)pagehandle = pdfReader.getPage(0)print(pagehandle.extractText()) Рейтинг: 0/5
Многообещающее начало, так как люди в восторге от этой библиотеки. Документация тоже хорошая.
К сожалению, в последней версии есть ошибка, которая выдает ошибку каждый раз, когда вы пытаетесь извлечь текст из PDF. После сообщения об ошибке на форуме разработчиков библиотеки может быть исправление в работе. Скрещенные пальцы.
Оценка: 2/5
Apache Tika имеет библиотеку Python, которая, по-видимому, позволяет извлекать текст из PDF-файлов. Установить библиотеку Python достаточно просто, но она не будет работать, если у вас не установлена JAVA.
По крайней мере, такова теория. Я не хотел устанавливать JAVA; поэтому я остался на: «RuntimeError: невозможно запустить сервер Tika». Ошибка .
Согласно этому среднему блогу (без принадлежности), однако, как только вы заработаете, это потрясающе. Итак, давайте оценим 2/5.
Итак, давайте оценим 2/5.
Код будет выглядеть примерно так:
from tika import parserfile = r'D:\examplepdf.pdf'file_data = parser.from_file(file)text = file_data['content']print(text)
Рейтинг: 5/5
Когда я начал терять веру в существование простой в использовании библиотеки Python для извлечения текста из PDF-файлов, мне попалась pdfPlumber.
Документация не так уж и плоха; через несколько минут все заработает. Результаты настолько хороши, насколько это возможно.
Однако стоит отметить, что в библиотеке конкретно указано, что она лучше всего работает с PDF-файлами, созданными машиной, а не с отсканированными документами; что я и использовал.
Код:
импортировать pdfplumberwith pdfplumber.open(r'D:\examplepdf.pdf') как pdf:
first_page = pdf.pages[0]
print(first_page.extract_text())
Рейтинг: 4/ 5
Буду честен; типичным питоническим способом я взглянул на документацию (дважды!) и не понял, как я должен был запустить этот пакет; это включает в себя pdfMiner (не версию 3, которую я также рассматриваю здесь). Я даже установил его и попробовал несколько вещей, но безуспешно.
Я даже установил его и попробовал несколько вещей, но безуспешно.
Увы, мне на помощь приходит добрый незнакомец из StackOverflow. После того, как вы ознакомитесь с приведенным примером, вам действительно будет легко следовать. О, и результаты так хороши, как и следовало ожидать:
Код можно найти в связанном посте StackOverflow.
Другой способ решить эту проблему — преобразовать PDF-файл в изображение. Это можно сделать либо программно, либо сделав скриншот каждой страницы.
Когда у вас есть файлы изображений, вы можете использовать библиотеку tesseract для извлечения из них текста:
Как извлечь текст из изображений с помощью Python
Научитесь извлекать текст из изображений в 3 строки кода
Направлениеdatascience.com
Прежде чем идти, если вам понравилась эта статья, вам также может понравиться:
Обучение использованию индикаторов выполнения в Python
Знакомство с 4 различными библиотеками (командная строка и пользовательский интерфейс)
в направлении datascience. com
com
Создание пользовательского интерфейса Python для сравнения данных
Как быстро включить вашу нетехническая команда для сравнения данных
в направлении datascience.com
4 бесплатных метода преобразования PDF в текст на Mac
Пользователи PDNob по всему миру
2 582 819
Содержание
Домашняя страница
Рэйчел Джонс|2023-01-12 |
4 мин чтения
В настоящее время все спрашивают, как преобразовать PDF в текст Mac ? Если у вас возникли проблемы с выделением текста в PDF-файле на Mac, не беспокойтесь — извлечь текст из PDF-файла на Mac очень просто. В этой статье я покажу вам, как это сделать, и это займет всего несколько секунд!
- 1. Предварительный просмотр
- 2. Автомат
- 3. Документы Google
- 4. Переводчик изображений PDNob
1. Конвертируйте PDF в текстовый файл с помощью предварительного просмотра
Существует ряд доступных инструментов, которые могут помочь вам извлечь текст из PDF на Mac. Самый простой и понятный вариант — использовать предварительный просмотр; Mac Preview очень легко конвертирует PDF в текст, который входит в состав macOS.
Самый простой и понятный вариант — использовать предварительный просмотр; Mac Preview очень легко конвертирует PDF в текст, который входит в состав macOS.
Чтобы извлечь текст с помощью предварительного просмотра:
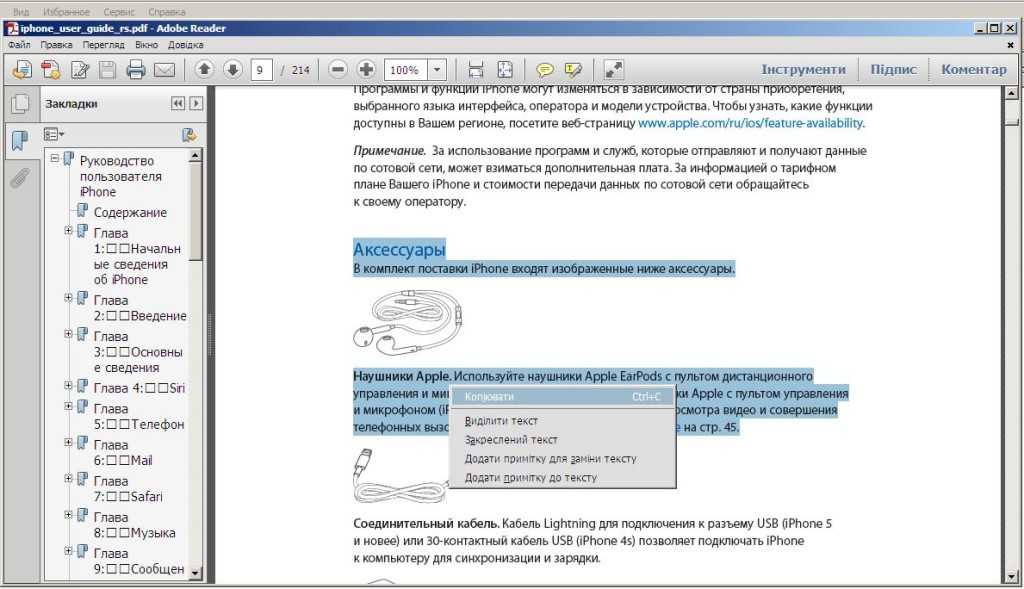
Просто откройте файл PDF в режиме предварительного просмотра и выберите инструмент «Выбрать» на панели инструментов.
Затем выберите текст, который вы хотите извлечь, и скопируйте его в буфер обмена.
Вы можете вставить текст в новый документ или использовать его по своему усмотрению!
Это сделано! Извлекать текст из PDF на Mac очень просто.
2. Конвертируйте PDF в текст бесплатно с помощью Automator
Этот метод является одним из самых простых и быстрых способов извлечения текста из PDF-изображения Mac без установки внешнего профессионального сканера OCR. Это широко используемая и заслуживающая доверия программа со встроенной функцией OCR.
Если вы хотите извлечь текст из PDF-файла с помощью Automator, вы также можете сделать это очень легко.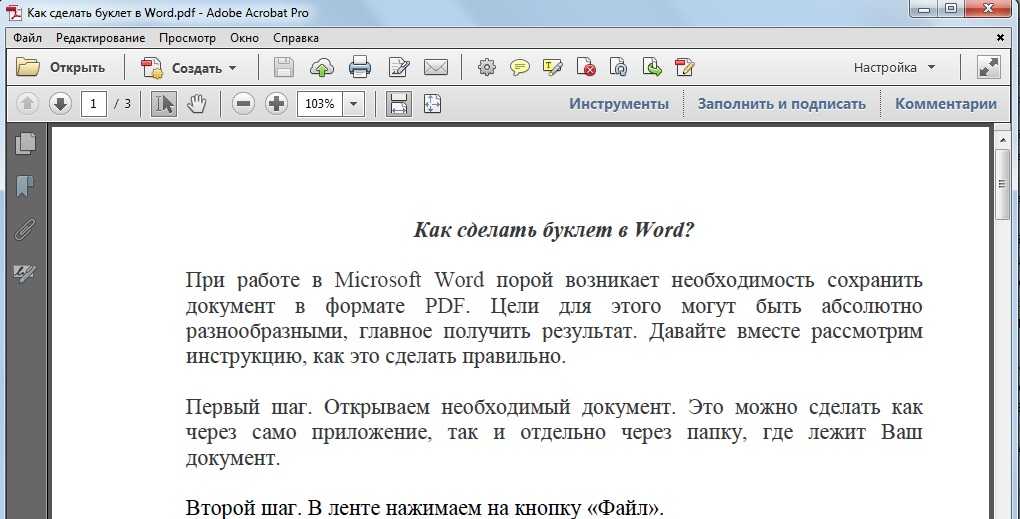
Вот как:
Откройте Automator и выберите тип «Рабочий процесс».
Откройте Automator и выберите тип «Рабочий процесс».
Теперь перетащите действие «Открыть PDF» в рабочий процесс и выберите нужный файл PDF.
Наконец, нажмите кнопку «Выполнить», чтобы извлечь текст из PDF!
3. Конвертировать pdf в текстовые гугл документы
Если вы хотите извлечь текст из PDF-изображения Mac, используя документы Google, это очень просто.
Вот как:
Откройте Документы Google и нажмите кнопку «Создать».
Выберите «Загрузить файл» и выберите нужный файл PDF.
После загрузки файла щелкните правой кнопкой мыши миниатюру изображения файла и выберите «Открыть с помощью» > «Документы Google». Он будет автоматически преобразован в текст.
Валлах!! ваш текст был извлечен из PDF.
4.
 Конвертируйте pdf в word с помощью PDNob Image Translator
Конвертируйте pdf в word с помощью PDNob Image Translator
Все сталкиваются с проблемами при копировании и переводе PDF-файлов, вы не можете скачать некоторые PDF-файлы, вы не можете выбрать текст в PDF Mac, но теперь это решено. Существует ряд бесплатных онлайн-инструментов, которые помогут вам извлечь текст из PDF на Mac. Самый популярный — PDNob Image Translator.
Как использовать этот инструмент:
Чтобы начать, нажмите Command + 1 на Mac или выберите Захват текста в строке меню.
Сделайте снимок запрошенного текста, и выбранный будет немедленно распознан.
Завершите перевод целевого текста, щелкнув символ перевода.
Преобразование PDF в текст на Mac
Преимущества этого инструмента:
- Извлечение текста из изображения : Использование технологии снимков экрана и оптического распознавания символов для извлечения данных из отсканированных изображений.
- Извлечение текста из PDF : Использование снимков экрана и методов оптического распознавания символов для извлечения данных из отсканированных PDF-файлов.
- Языковая поддержка OCR : Поддерживает распознавание 8 языков.
- Переводчик изображений : перевод текста OCR на другой язык.
- Перевести более чем на 100 языков : Участвуйте в переводе бесплатно!

PDNob — это бесплатный онлайн-инструмент, который поможет вам извлечь текст из PDF на Mac. Он прост в использовании и поддерживает более 100 языков. Вы также можете перевести текст на другой язык, используя значок перевода. Теперь, когда вы не можете выделить текст в PDF mac, войдите в PDNob.
Заключение
Существует несколько способов преобразования pdf в текст mac . Но если вы хотите извлечь текст из изображения, PDF-файла или любой части экрана вашего Mac, вы можете попробовать PDNob Image Translator. Извлекать текст из PDF на Mac теперь легко и удобно! Теперь у вас есть ответ на вопрос, как скопировать текст из pdf mac.
часто задаваемые вопросы
В: Какие есть другие варианты извлечения текста из PDF на Mac?
О. Существует ряд других инструментов и методов для извлечения текста из PDF на Mac, включая Automator, Adobe Acrobat Pro, Google Docs и другие. У каждого метода есть свои плюсы и минусы, поэтому важно учитывать ваши конкретные потребности и предпочтения при выборе инструмента или метода. Некоторые инструменты могут лучше подходить для извлечения текста из отсканированных документов или файлов изображений, в то время как другие могут предлагать расширенные возможности редактирования и добавления аннотаций. В конечном счете, лучший вариант будет зависеть от вашей уникальной ситуации.
В: Почему я не могу использовать предварительный просмотр для преобразования PDF в текст на Mac?
Если у вас возникли проблемы с выделением или копированием текста из PDF-файла в программе «Просмотр» на Mac, вы можете попробовать следующее.
- Проверьте, требует ли файл PDF пароль для редактирования.