Как из pdf вытащить шрифты: Извлечь шрифты из PDF Онлайн 100% бесплатно
Извлечение шрифтов из PDF / Хабр
Сразу следует сказать, что лучшей информации по формату, чем много мегабайтный PDFReference с сайта Adobe не существует. Для тех, кто пишет на С++ есть готовое решение — XPDF. В линуксе это самая полнофункциональная замена продуктам Adobe. Русскоязычные материалы на эту тему поверхностны и служат лишь для ознакомления, а не для практической работы. Но я рассчитываю, что с ними, а лучше с PDFReference вы уже знакомы. Я решил описать конкретный упрощенный пример извлечения из файла PDF truetype шрифтов, потому что этот вопрос очень часто звучит в сети и остается без ответа. Мне известна только одна такая программа, которая работает с ошибками и без исходников. Напоминаю, что пользоваться извлеченными шрифтами не всегда законно, можно только выводить встроенным шрифтом текст из документа.
Кто интересовался вопросом, то знают, что PDF состоит из заголовка, таблицы перекрестных ссылок (XRef), тела и трайлера (прицепа). Все элементы кроме заголовка могут быть разбросаны частями и в нескольких экземплярах по всему документу. Для начала надо прочитать таблицу XRef. Рекомендую оформить её классом. Для поиска адреса таблицы читаем файл с конца, пока не встретим тег %%EOF. Продолжаем читать задом наперед до тега startxref. теперь можно считать число, которое следует за этим тегом.
Все элементы кроме заголовка могут быть разбросаны частями и в нескольких экземплярах по всему документу. Для начала надо прочитать таблицу XRef. Рекомендую оформить её классом. Для поиска адреса таблицы читаем файл с конца, пока не встретим тег %%EOF. Продолжаем читать задом наперед до тега startxref. теперь можно считать число, которое следует за этим тегом.
Вот пример конца файла:
startxref
173
%%EOF
число 173 — это смещение от начала данных файла к началу первой таблицы XRef. Переместившись в эту точку, мы видим что-то вроде этого:
xref
7628 42
0000000016 00000 n
0000001195 00000 f
и тд.
На 7628 пока не будем обращать внимание (это имя первого объекта, где записана информация о количестве страниц, например, а так же много чего другого). А 42 — это количество записей в данной части таблицы. Далее совсем просто: считываем в 10 байтный буфер первое слово, пропускаем пробел и считываем 5 байтный буфер, читаем отдельный символ. И так 42 раза. Преобразованные к целым строки имеют следующее значение — смещение от начала данных к ссылочному объекту, номер генерации. Последний символ интерпретируется так: n — объект используется, f — объект не используется, но как я говорил, у таблицы XRef могут быть продолжения в потоке файла. Как их найти? после таблицы всегда следует тег trailer. Когда он встретится надо искать строку /Prev — если она есть, то следом идет смещение к следующей таблице.
И так 42 раза. Преобразованные к целым строки имеют следующее значение — смещение от начала данных к ссылочному объекту, номер генерации. Последний символ интерпретируется так: n — объект используется, f — объект не используется, но как я говорил, у таблицы XRef могут быть продолжения в потоке файла. Как их найти? после таблицы всегда следует тег trailer. Когда он встретится надо искать строку /Prev — если она есть, то следом идет смещение к следующей таблице.
/Prev 4025745
Таким образом прочитываем все таблицы, если их больше одной. Закончить чтение можно, если в следующем трайлере будет отсутствовать ключ /Prev. Признаком последней таблицы может служить и то, что она начинается с записи 0000000000 65535 f. Надо сказать, что мы читаем таблицы задом наперед, последняя при чтении является первой, которая появилась при создании самого документа, а первая при чтении возникла после последнего редактирования.
Используя полученные данные мы можем перемещаться к любому ссылочному объекту документа. Правда есть еще прямые объекты, адреса которых не внесены в XRef, но об этом позже. Теперь мы можем перебирать объекты документа, проверяя их тип и делая с ними, что душе угодно. Объект начинается так:
Правда есть еще прямые объекты, адреса которых не внесены в XRef, но об этом позже. Теперь мы можем перебирать объекты документа, проверяя их тип и делая с ними, что душе угодно. Объект начинается так:
7626 0 obj
содержимое объекта
endobj
7626 — номер (имя) объекта, а 0 — номер генерации, который должен совпадать с подобным значением в таблице ссылок для этого объекта. Как я понял, если объект меняется, редактируется, то и номер генерации увеличивается. Мы собрались искать шрифты, для этого надо прочитать словарь объекта, который представляет собой лексему, заключенную в теги <<… >>. Если элементы словаря имеют такую структуру, например:
/FirstChar 32
где слово после слеша — ключ, а необязательное значение после пробела — значение. При парсинге надо помнить, что значение может содержать любые данные, любой вложенности, в том числе и другие словари. Так что рекурсию вам в руки, впрочем, можно и без рекурсии, если мы работаем над конкретной задачей извлечения шрифтов. Указанное значение может также включать вложенные или не вложенные элементы следующих типов:
Указанное значение может также включать вложенные или не вложенные элементы следующих типов:
(… ) -текстовые строки
<… > — hex-строки
[… ] — массивы
Строка значения продолжается до следующего слеша или до перевода строки. Чтобы идентифицировать объект шрифта надо найти в словаре комбинацию:
/Type /Font
Теперь фильтруем Truetype шрифты по содержанию в словаре последовательности:
/Subtype /TrueType
Остальные ключи игнорируем, потому что мы просто хотим извлечь шрифты. Но самого шрифта мы в этом объекте, скорее всего не найдем. Только набор ненужных нам ключей. Читаем один из них:
/FontDescriptor 1675 0 R
Если такой ключ отсутствует, то шрифт внешний и не встроен в документ. Далее номер генерации этого объекта, а символ R обозначает, что это ссылка. Таблицу XRef мы уже прочитали и теперь можем переместиться к данным шрифта, через поиск смещения для объекта с номером 1675. Правда, возможен такой вариант:
/FontDescriptor << словарь и (или) данные шрифта >>
Будем считать, что мы переместились по ссылке к прямому объекту. В его словаре должны быть такие ключи:
В его словаре должны быть такие ключи:
/Type /FontDescriptor
В этом объекте тоже много полезных сведений о шрифте, но самого шрифта опять нет. Не моя вина — все претензии к компании Adobe. Нам нужен такой ключ
/FontFile2 1676 0 R
Знакомая конструкция. Переходим к следующему объекту. Если мы все сделали правильно, то это потоковый объект. Он состоит из словаря потока и из бинарных данных, заключенных между тегами stream… endstream. Вот тут надо сказать, что наличие бинарных данных не дает использовать готовые текстовые парсеры. Перепробовал много и пришлось написать свой с нуля. Бинарные данные можно считывать разом, так как в словаре потока имеется ключ /Length с длиной потока. Если попробовать сохранить извлеченный поток в файл с расширением TTF, то система объявит, что это никакой не шрифт. Все правильно, надо его разжать.
Шрифт чаще сжат с помощью zip, но для верности можно это проверить по наличию ключа /FlateDecode. Если работаем в Delphi, то используем стандартный ZLib. Мы можем получить размер буфера для разжатых данных из словаря потока по ключу /Length2. Ну и нужно знать, что встроенный в документ шрифт содержит только те глифы, которые в документе используются.
Мы можем получить размер буфера для разжатых данных из словаря потока по ключу /Length2. Ну и нужно знать, что встроенный в документ шрифт содержит только те глифы, которые в документе используются.
Думаю, что после этих наметок можно брать в одну руку hex-вьвер, в другую — PDFReference и стоить собственный АкробатРидер.
Извлечение шрифта из PDF | Render.ru
Guest
#1
#1
Господа, сабж.
Можно ли в принципе извлечь из ПДФа встроенный в него шрифт? Интересует извлечение либо в виде шрифтового файла, либо как просто вектор.
Guest
#2
#2
В Акробате есть Text Select Tool [V] нажимаешь, выжеляешь, копируешь. ..
..
Guest
#3
#3
>>> нажимаешь, выжеляешь, копируешь
Зачем, что, куда??? Вопрос то о другом совсем.
=====================================
Повторяю. Есть файл ПДФ. В него встроен шрифт. В системе, да и вообще у меня такого шрифта нет. Единственный способ, до которого я дошел — растеризация в Шопе, втягивание в Илл и трассировка по средством «Силуэта»… Но, сами понимаете, не супергуд это… Есть ли другой способ выдрать этот шрифт в виде шрифтового файла, либо, просто вектора.
=====================================
Ну а про Text Select Tool [V] я, извини, знаю и сам. Тем более, как надо было читать вопрос, что бы дать такой ответ?..
Тем более, как надо было читать вопрос, что бы дать такой ответ?..
Guest
#4
#4
У меня недавно сходная проблема была:
http://www.graphics.ru/forum/read.php?f=26&i=5446&t=5446
Есть такая штука — TransverterPro:
www.techpool.com
Экспортирует в том числе и в формат *.ai. При этом теряет оригинальные установки оверпринт.
Доступная к скачиванию версия работает 7 дней
Насчет Illustrator CS — не проверял, не знаю.
Guest
#5
#5
Ну извини!
Не понял!
Guest
#6
#6
Блин, вроде писал, куда-то сообщение делось. ..
..
Ну да ладно. Короче моя вина, недочитал, панику поднял…
Vldmr, спасибо, но в свете описанного и прочитанного — не слишком и даже для моей конкретной задачи не в оверпринтах дело… Идеально подошел вариант http://graphics.ru/forum/read.php?f=5&i=14897&t=14896. Вобчем супер.
СПАСИБО NETIK! Решение ну просто-таки… Век живи, блин… и все равно дураком помрешь… )))
СПАСИБО! Ну и Акробат Ридер 3 — форева!!!
netik
Активный участник
#7
#7
Благодарности принял
Guest
#8
#8
А если файл не для Акробат 3, что делать будешь?
Как я понимаю он сможет открыть, а следовательно и вытащить шрифт, если сохранен в PostScript 1, а из более поздних версиях ничего не получится.
Как мне сказал один знакомый полиграф. Адобе наоборот стремится к тому, что из пдф ничего нельзя было достать!
Guest
#9
#9
Предупреждаю сразу, писал не я.
Достать отттуда шрифты можно, но вау как непросто. Вряд ли стоит браться, если дальнейшее не понятно. Имеенно чтобы не было легко достать шрифты и придумали абобцы пдф.
А так:
— напечатать PDF в PS
— выкусить текстовым редактором ресурс шрифта. Сохранить с расширением .pfa (PS Font ASCII)
— преобразовать в . pfb (PS Font Bin) — есть утилиты
pfb (PS Font Bin) — есть утилиты
— открыть шрифтовым редактором и сгенерить новые .pfm и прочее. Вся инфа о трекингеи кернинге будет потеряна.
Так что не советую. Сам баловался из любознательности, получить так полноценный шрифт не удастся. Лучше найти/купить родной/близкий.
Была идея наглее. Ведь АТМ создает все эти виртуальные шрифты в своей временной папке. А потом стирает. Возможно, стертое можно восстановить. Проще, но не пробовал. Стоит помнить, что в публикацию могут включаться не все символы используемого шрифта…
Отвечал Mike Kouvchinov
Guest
#10
#10
>>> Адобе наоборот стремится к тому, что из пдф ничего нельзя было достать!
Дык это и ежу понятно. Тут и «знакомый полиграф» не нужен. Однако в этом мои стремления несколько с адобовскими расходятся.
Тут и «знакомый полиграф» не нужен. Однако в этом мои стремления несколько с адобовскими расходятся.
>>> ничего не получится.
Всё, что требуется, получается великолепно.
ЗЫ. «Полиграф», кстати, есть т.н. детектор лжи.
fasimba
Пользователь сайта
#11
#11
все классно тока ссылки на графикс не работают — очень интересно что это был за вариант который идеально подошел? (http://graphics.ru/forum/read.php?f=5&i=14897&t=14896)
если автор случайно забредет в этот форум снова — было бы здорово оживить тени давно ушедших лет
alexdoors
Пользователь сайта
#12
#12
///Интересует извлечение либо в виде шрифтового файла, либо как просто вектор. /// Не знаю актуален ли еще вопрос, но
/// Не знаю актуален ли еще вопрос, но
насчет шрифтового файла, конечно проблематично будет, а вот простым вектором можно. Лично я в таких случаях курвлю тексты в акробате, после чего ПДФку можно спокойно открыть в Иллюстраторе CS3, а там уже работать как с обычной аишкой, убивая все лишнее, оставляя текст.
Просмотр списка встроенных шрифтов в файле PDF с предварительным просмотром
спросил
Изменено
4 года, 11 месяцев назад
Просмотрено
73 тысячи раз
В Acrobat Reader я могу выбрать «Файл» > «Свойства», чтобы просмотреть все метаданные для открытого файла PDF: программа, создавшая документ, информация об авторе, встроенные шрифты и т. д.
Предварительный просмотр OS X также может отображать метаданные, хотя и в более ограниченном подмножестве (в меню «Инструменты» > «Показать инспектор»).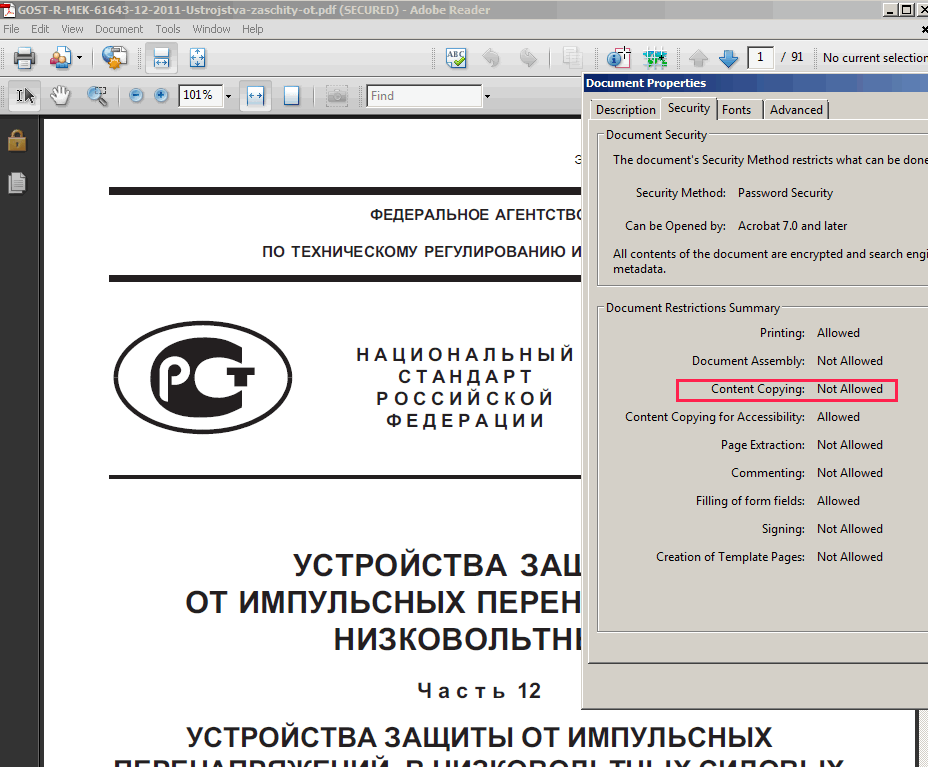 Однако вы не можете видеть информацию о встроенном шрифте с помощью предварительного просмотра.
Однако вы не можете видеть информацию о встроенном шрифте с помощью предварительного просмотра.
Есть ли способ в OS X (желательно с предварительным просмотром, а не с Acrobat), чтобы увидеть, какие шрифты встроены в файл PDF?
- предварительный просмотр
- встроенные шрифты
1
Запустите любую команду из терминала или командной строки.
MacOS
строки /path/to/document.pdf | grep -i имя_шрифта
Примечание. В MacOS может потребоваться сначала установить инструменты командной строки.
Windows
findstr FontName C:\path\to\document.pdf
9
Вы также можете использовать pdffonts , который можно установить с помощью brew install poppler или brew install xpdf .
$ файл pdffonts.pdf имя тип кодировка emb sub uni идентификатор объекта ------------------------------------ ---------------------------- --- ---------------- --- --- --- --------- GFEDCB+MyriadSet-Medium CID TrueType Identity-H да да да 304 0 GFEDCB+MyriadSet-Bold CID TrueType Identity-H да да да 310 0 GFEDCB+MyriadSet-MediumItalic CID TrueType Identity-H да да да 6590 GFEDCB+Menlo-Regular CID TrueType Identity-H да да да 664 0 ZapfDingbats Type 1 Custom нет нет да 665 0 ZapfDingbats Type 1 Custom нет нет да 666 0
5
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
Как извлечь шрифты из PDF
Чтение файла PDF с красивыми шрифтами может вдохновить вас на создание собственного документа с этими символами. Извлечение шрифта может показаться невозможным, но прелесть файлов PDF заключается в том, что они встраивают шрифты, используемые в виде данных. PDF-файлы несут с собой шрифты, чтобы пользователи и читатели, такие как вы, могли просматривать файл с правильным шрифтом.
Форматированный текст, шрифты, мультимедиа и изображения — это лишь несколько вещей, которые поддерживает PDF, и их можно извлечь для собственного использования. Начнем с того, как получить шрифты или хотя бы узнать эти шрифты с помощью некоторых сторонних приложений.
1. Идентификация шрифта с помощью MyFonts.com
Если вы не являетесь экспертом в области шрифтов и не уверены в том, какой тип имеет ваш PDF-файл, вы можете попробовать использовать MyFonts.com What the Font. Этот веб-сайт предоставляет программное обеспечение для распознавания шрифтов, которое поможет вам определить, что это за шрифт, просто загрузив фотографию шрифта. Просто сделайте скриншот раздела документа и загрузите его на сайт. После загрузки веб-сайт предоставит рекомендуемые шрифты из своей библиотеки, которые вы также можете загрузить бесплатно.
Этот веб-сайт предоставляет программное обеспечение для распознавания шрифтов, которое поможет вам определить, что это за шрифт, просто загрузив фотографию шрифта. Просто сделайте скриншот раздела документа и загрузите его на сайт. После загрузки веб-сайт предоставит рекомендуемые шрифты из своей библиотеки, которые вы также можете загрузить бесплатно.
2. Шрифт Moose
На этом сайте вы можете загрузить изображение или указать URL-адрес изображения, а затем нажать «Загрузить». После загрузки сайт попытается распознать слова или символы (которые вы также можете выбрать), а затем предложит вам шрифты с соответствующим автором, которые соответствуют символам в загруженном файле. Он не даст вам прямую ссылку, но даст вам прямое имя, которое вы можете использовать для поиска.
3. ИзвлечьPDF
Хотите программу для распознавания шрифтов, для которой не нужен снимок экрана? Вот тот, который позволяет напрямую загружать файл PDF. ExtractPDF — это программа для работы с файлами PDF, предназначенная для извлечения вложений из PDF-файлов, таких как шрифты, изображения, текст и метаданные. После загрузки PDF-файла или URL-адреса на сайт программное обеспечение идентифицирует шрифт и позволяет вам сохранить его в виде файла шрифта, который вы также можете установить непосредственно на свой компьютер.
После загрузки PDF-файла или URL-адреса на сайт программное обеспечение идентифицирует шрифт и позволяет вам сохранить его в виде файла шрифта, который вы также можете установить непосредственно на свой компьютер.
4. FontForge
Другим экстрактором файлов с поддержкой PDF является FontForge. Это программное обеспечение требует установки на ваш компьютер и ориентировано в основном только на шрифты. Это бесплатное программное обеспечение, которое позволяет пользователям создавать свой документ и извлекать шрифты, просто загружая PDF-файл в установленное программное обеспечение. Обязательно выберите опцию «извлечь из PDF»!
Извлечение дополнительных файлов и управление PDF-файлами
Если ваш PDF-файл является отсканированным PDF-файлом, шрифты и символы могут не распознаваться программным обеспечением шрифтов, поэтому убедитесь, что вы конвертируете эти отсканированные PDF-файлы с помощью инструмента OCR от DeftPDF! При преобразовании с помощью этого инструмента файл PDF преобразуется из файла, состоящего только из точек, в файл, читаемый компьютером.